

 Protecting your learning management system from downtime is one thing. Saving your data in a safe place for recovery after a disaster is another. To properly protect your system you need both. A back-up takes a copy of your existing system and stores it for later recovery. Failover means that if the server your learning management system runs on fails, or is overextended, it fails over to another server automatically. I’ve discussed back-ups in another blog post. So this post will deal with failover systems.
Protecting your learning management system from downtime is one thing. Saving your data in a safe place for recovery after a disaster is another. To properly protect your system you need both. A back-up takes a copy of your existing system and stores it for later recovery. Failover means that if the server your learning management system runs on fails, or is overextended, it fails over to another server automatically. I’ve discussed back-ups in another blog post. So this post will deal with failover systems.
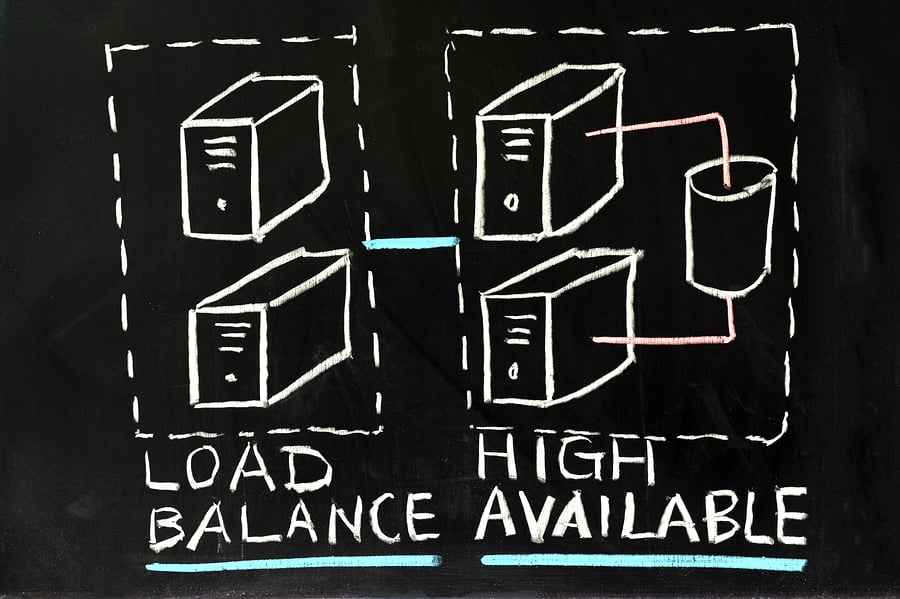
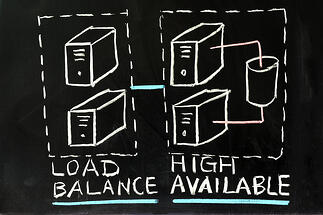
Basically, a failover system acts like a switch between two or more different servers. When a reserve server senses a failover state from the production server running your LMS, it takes over the traffic from the failed server. There are a number of ways you can set up failover systems. For example, some require human intervention to switch from one server to the next. However, for the hosted LMSs we serve, we prefer automatic failover to ensure systems do not ever go down. In our world, ‘Basic’ failover means a standby server can pick up the slack when your production server goes down. Even with the best systems available something can always go wrong so planned redundancy is a wise choice. There are more advanced versions of failover which relate to load balancing to reduce system slowdowns in addition to preventing a wholesale crash.
Failover for Server Overloads
If you have increased traffic to your server, we can spread that traffic out to alternate servers to, avoid an overload. Server overloading can lead to a crash at worst and seriously slow response times at best. Load balancing spreads traffic from one server to multiple servers. In our world ‘Advanced’ failover means load balancing as well as failover. There are a couple of common methods for determining how network traffic will be rerouted.
We can distribute traffic based on the geographic location of learners, so all your west coast traffic can go to your west coast servers, and all of your east coast traffic goes to your east coast servers. This may not make sense, however if your learners are all mostly located in one place. In that case, we might use the weighted round robin approach to load balancing.
The weighted round robin approach polls all servers on a regular basis to determine which are experiencing lighter loads and which are experiencing heavy loads. Those with heavy loads can then divert their traffic to the servers with lighter loads. Weighted Round-robin gives us control over where your traffic gets directed, and can work in conjunction with geographic balancing. The great thing about load balancing is that it continually optimizes resources to improve response times and of course, if you have more than one server failover is covered too.
We recommend you consider basic or advanced failover based on the number of users you have and what kind of content you are delivering.
